[Из песочницы] «Dense_rank()» vs «Max()» или расследование с неожиданным концом
Здравствуйте, коллеги.В этой статье я расскажу о своих изысканиях в вопросе: «А что же лучше: dense_rank () или max ()» и, конечно, почему эти изыскания завершились с неожиданным, по крайней мере для меня, результатом.Предыстория: Так сложились звезды, что мне нужно сейчас искать работу. Перед каждым собеседованием я изучаю компанию, в которую меня пригласили, дабы понимать чем занимается компания, чему я научусь если мне сделают оффер и т.д. И вот, в один прекрасный момент, мне пришло приглашение на интервью, на позицию PL/SQL разработчика, от одной прекрасной компании. Прочитав о ней, мне показалось, что я влюблен и хочу там работать. Когда же я пришел на само интервью и в тот момент, когда все к интервью уже готово, а оно еще не началось просто потому что люди знакомятся, hr предлагает кофе и т.д., я уже понял, что хочу, очень хочу, тут работать.За все интервью с тимлидом, мне один раз предложили написать простенький запрос, в остальном же все проходило в режиме: вопрос-ответ.Задачка звучала так: «У нас есть таблица операций, в ней 4 столбца: id операции, id клиента, дата операции, сумма операции. Нужно вывести последние операции по каждому клиенту с максимальной суммой за определенный период».И я, конечно, начал лихорадочно соображать, как же написать так, чтобы было красиво и эффективно. А кроме оракла я еще работал с терадатой и в тот момент мой мозг выдал вот такой запрос: Скрытый текст /*id операции — oper_id, id клиента — client_id, дата операции — input_date, сумма операции — amount*/ select t.* , max (t.amount) over (partition by t.client_id) as m_a from some_table t qualify oper_id = max (t.oper_id) over (partition by t.client_id) where m_a = amount И в случае с терадатой такое бы сработало, но не с ораклом, увы. И четко помня, что «qualify» в оракле нет, я написал на бумажке что то на подобии: Скрытый текст select t.* from some_table t where amount = max (t.oper_id) over (partition by t.client_id) На что мне был задан вопрос: «А почему была использована max (), а не dense_rank ()?», не помню что я точно ответил, но звучало это приблизительно так: «max () я использовал чаще и могу, более-менее точно, представить, что он мне вернет, в отличии от dense_rank ()». Дальше описывать интервью не буду, скажу только, что мне, конечно же, отказали. Позже, уже дома, в попытках проанализировать все и понять ошибки, я пришел к выводу, что слишком сильно хотел там работать и переволновался, иначе ту кашу, творившуюся у меня в голове во время интервью, я объяснить не могу. Это было нечто сродное с тем ощущением, когда школьник пытается поговорить с девочкой, которую он тайно любит еще с садика, но эти попытки все больше и больше ставят его в неловкое положение. Так же и я, стараясь выглядеть спокойным и адекватным, показал себя как никудышный специалист. В общем, я решил для себя выяснить, что лучше использовать dense_rank () или max () при решении такой задачи.Исследование Если вы хотите собственными глазами увидеть все, что я напишу и собственными руками это все потрогать — я подготовил набор скриптов создания данных для теста: Скрытый текст /*создаем табличку*/ create table habr_test_table_220414 ( oper_id number, client_id number, input_date date, amount number constraint habr_test_table_220414_pk primary key (oper_id) ); grant all on habr_test_table_220414 to public;
/*Для того, чтобы поле oper_id было уникальным — создадим последовательность*/ create sequence habr_test_sequence_220414 increment by 1; grant all on habr_test_sequence_220414 to public; /*и триггер, который при вставке в таблицу, будет подменять значение oper_id на следующий элемент последовательности*/ create trigger habr_test_trigger_220414 before insert on habr_test_table_220414 for each row begin : new.oper_id:= habr_test_sequence_220414.nextval; end;
/*Наполняем табличку данными и да поможет нам рандом заполнить ее разнообразными значениями*/
/*Для теста примем период в год, также рассмотрим ситуацию с 10-тью клиентами*/
/*Для того, чтобы нам не выдавался cost = 3, наполним табличку 20000 строк, если кому то хочется*/
/*больше или меньше — разделите желаемое количество пополам и присвойте это значение переменной counter */
declare
counter number:= 10000;
i number:= 0;
begin
loop
insert into habr_test_table_220414
(
client_id
, input_date
, amount
)
values
(
trunc (dbms_random.value (1, 11))
, to_date (trunc (dbms_random.value (to_char (date '2013–01–01','j'), to_char (date '2013–12–31','j'))),'j')
, trunc (dbms_random.value (1, 100000))
);
exit when (i = counter);
i:= i + 1;
end loop;
commit;
/*Дабы обеспечить возникновение ситуации, когда мы имеем одинаковые суммы по операциям одного клиента*/
/*выполним такую команду:*/
insert into habr_test_table_220414 select * from habr_test_table_220414;
commit;
/*а о уникальности id операции позаботится триггер*/
end;
Итак, тестовые данные созданы, пора приступать к, собственно, самим запросам. Для того, чтобы не обрезать наши 20000 строк, мы не будем ограничивать нашу выборку каким-то определенным периодом, нам ведь важно понять какой метод лучше и эффективнее, а
where input_date between to_date ('01.01.2013','dd.mm.yyyy') and to_date ('01.05.2013','dd.mm.yyyy')
мы можем добавить и потом.
Запрос с использованием max ()
select * from
(
select c.*
, max (c.oper_id) over (partition by c.client_id) as m_o/*max_operation*/
from
(
select t.*
, max (t.amount) over (partition by t.client_id) as m_a/*max_amount*/
from habr_test_table_220414 t
) c
where c.m_a = c.amount
) where m_o = oper_id;
Запрос с использованием dense_rank ()
select * from
(
select c.*
, dense_rank () over (partition by c.client_id order by c.oper_id desc) as m_o/*max_operation*/
from
(
select t.*
, dense_rank () over (partition by t.client_id order by t.amount desc) as m_a/*max_amount*/
from habr_test_table_220414 t
) c
where c.m_a = 1
) where m_o = 1;
Предварительные планы для этих запросов (получено в pl/sql developer): Max:
Скрытый текст
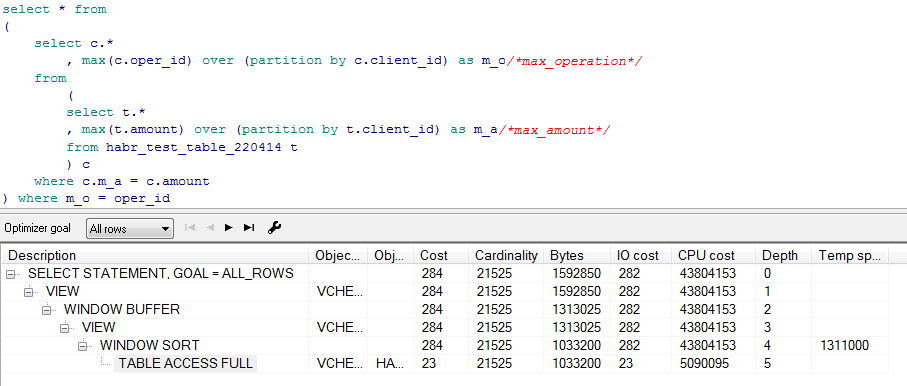 Dense_rank:
Скрытый текст
Dense_rank:
Скрытый текст
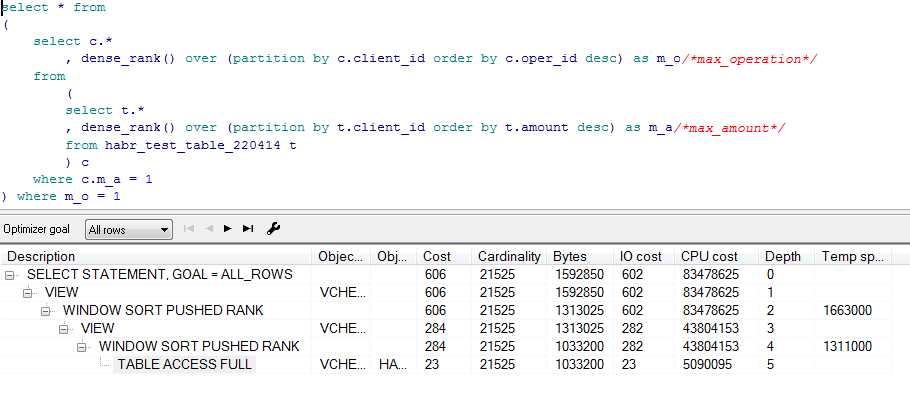 Но это предварительные планы, реальные получим при помощи утилиты SQLTUNE:
Подготовка:
/*Для запроса с max ()*/
DECLARE
my_task_name varchar2(30); my_sqltext clob; rep_tuning clob;
BEGIN
Begin
DBMS_SQLTUNE.DROP_TUNING_TASK ('my_sql_tuning_task_max');
exception when others then NULL;
end;
MY_SQLTEXT:=
'select * from
(
select c.*
, max (c.oper_id) over (partition by c.client_id) as m_o/*max_operation*/
from
(
select t.*
, max (t.amount) over (partition by t.client_id) as m_a/*max_amount*/
from habr_test_table_220414 t
) c
where c.m_a = c.amount
) where m_o = oper_id';
MY_TASK_NAME:=DBMS_SQLTUNE.CREATE_TUNING_TASK (SQL_TEXT => my_sqltext,
TIME_LIMIT => 60, --задается время выполнения в секундах
TASK_NAME =>'my_sql_tuning_task_max', DESCRIPTION=> my_task_name,
SCOPE => DBMS_SQLTUNE.scope_comprehensive);
begin
DBMS_SQLTUNE.EXECUTE_TUNING_TASK ('my_sql_tuning_task_max');
exception when others then null;
end;
END;
Но это предварительные планы, реальные получим при помощи утилиты SQLTUNE:
Подготовка:
/*Для запроса с max ()*/
DECLARE
my_task_name varchar2(30); my_sqltext clob; rep_tuning clob;
BEGIN
Begin
DBMS_SQLTUNE.DROP_TUNING_TASK ('my_sql_tuning_task_max');
exception when others then NULL;
end;
MY_SQLTEXT:=
'select * from
(
select c.*
, max (c.oper_id) over (partition by c.client_id) as m_o/*max_operation*/
from
(
select t.*
, max (t.amount) over (partition by t.client_id) as m_a/*max_amount*/
from habr_test_table_220414 t
) c
where c.m_a = c.amount
) where m_o = oper_id';
MY_TASK_NAME:=DBMS_SQLTUNE.CREATE_TUNING_TASK (SQL_TEXT => my_sqltext,
TIME_LIMIT => 60, --задается время выполнения в секундах
TASK_NAME =>'my_sql_tuning_task_max', DESCRIPTION=> my_task_name,
SCOPE => DBMS_SQLTUNE.scope_comprehensive);
begin
DBMS_SQLTUNE.EXECUTE_TUNING_TASK ('my_sql_tuning_task_max');
exception when others then null;
end;
END;
/*Для запроса с dense_rank ()*/
DECLARE
my_task_name varchar2(30); my_sqltext clob; rep_tuning clob;
BEGIN
Begin
DBMS_SQLTUNE.DROP_TUNING_TASK ('my_sql_tuning_task_dense');
exception when others then NULL;
end;
MY_SQLTEXT:=
'select * from
(
select c.*
, dense_rank () over (partition by c.client_id order by c.oper_id desc) as m_o/*max_operation*/
from
(
select t.*
, dense_rank () over (partition by t.client_id order by t.amount desc) as m_a/*max_amount*/
from habr_test_table_220414 t
) c
where c.m_a = 1
) where m_o = 1';
MY_TASK_NAME:=DBMS_SQLTUNE.CREATE_TUNING_TASK (SQL_TEXT => my_sqltext,
TIME_LIMIT => 60, --задается время выполнения в секундах
TASK_NAME =>'my_sql_tuning_task_dense', DESCRIPTION=> my_task_name,
SCOPE => DBMS_SQLTUNE.scope_comprehensive);
begin
DBMS_SQLTUNE.EXECUTE_TUNING_TASK ('my_sql_tuning_task_dense');
exception when others then null;
end;
END;
/*К сожалению, что то сломалось и половина запросов в этом куске кода разукрашена цветом как строка*/
/*прошу прощения, не обращайте на это внимание*/
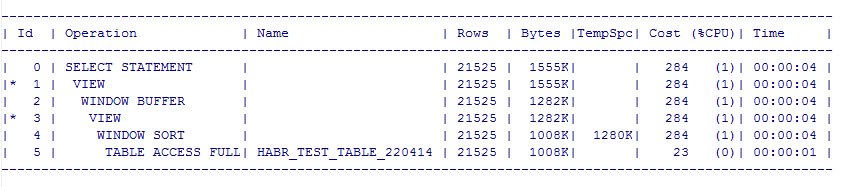
и выглядят эти реальные планы вот так:
Скрытый текст
SELECT DBMS_SQLTUNE.REPORT_TUNING_TASK ('my_sql_tuning_task_max') FROM DUAL;
 SELECT DBMS_SQLTUNE.REPORT_TUNING_TASK ('my_sql_tuning_task_dense') FROM DUAL;
SELECT DBMS_SQLTUNE.REPORT_TUNING_TASK ('my_sql_tuning_task_dense') FROM DUAL;
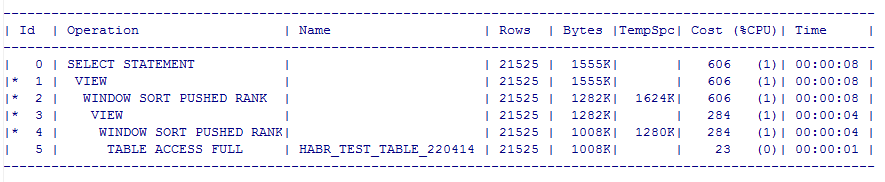 Помимо реального плана SQLTUNE также выдает рекомендации по оптимизации скрипта, в нашем случае он рекомендует собрать статистику, но так как табличка у нас одна, то и запросы находятся в одинаковых условиях.Предварительный итог
После всех этих манипуляций мне, как я надеюсь и вам, ясно что при решении этой задачи max () отрабатывает быстрее чем dense_rank () в 2 раза и съедает вдвое меньше процессорного времени. Ну оно то понятно итак, без планов и прочего, ведь max () это всего лишь поиск наибольшего, в то время как dense_rank () — это, в первую очередь сортировка, а уже потом нумерование.Но не это побудило меня писать статью.Внезапно
В процессе первоначального заполнения таблицы для теста, это я ведь для статьи сообразил скрипты, а в первый раз все происходило практически в ручном режиме, и для проверки состояния подопытной таблицы я использовал запрос с order by.
Скрытый текст
/*сначала было 10 инсертов и запрос*/
insert into habr_test_table_220414…;
…
…
insert into habr_test_table_220414…;
commit;
select * from habr_test_table_220414 t order by t.client_id;
/*потом несколько раз повторялся кусок:*/
insert into habr_test_table_220414 select * from habr_test_table_220414;
commit;
select * from habr_test_table_220414 t order by t.client_id;
/*вот так я и строил первые тестовые данные*/
После этого я модифицировал этот запрос до финального состояния «запрос с max ()», так и не убрав order by.
Вот что получилось:
select * from
(
select c.*
, max (c.oper_id) over (partition by c.client_id) as m_o/*max_operation*/
from
(
select t.*
, max (t.amount) over (partition by t.client_id) as m_a/*max_amount*/
from habr_test_table_220414 t
order by t.client_id
) c
where c.m_a = c.amount
) where m_o = oper_id
Позже я написал «запрос с dense_rank ()» и начал сравнивать планы, но заметив этот злополучный order by в запросе с max (), удалил order by, но cost его я уже увидел и запомнил. И когда увидел cost в запросе с max () без order by сильно удивился, ведь:
Предварительный план
Помимо реального плана SQLTUNE также выдает рекомендации по оптимизации скрипта, в нашем случае он рекомендует собрать статистику, но так как табличка у нас одна, то и запросы находятся в одинаковых условиях.Предварительный итог
После всех этих манипуляций мне, как я надеюсь и вам, ясно что при решении этой задачи max () отрабатывает быстрее чем dense_rank () в 2 раза и съедает вдвое меньше процессорного времени. Ну оно то понятно итак, без планов и прочего, ведь max () это всего лишь поиск наибольшего, в то время как dense_rank () — это, в первую очередь сортировка, а уже потом нумерование.Но не это побудило меня писать статью.Внезапно
В процессе первоначального заполнения таблицы для теста, это я ведь для статьи сообразил скрипты, а в первый раз все происходило практически в ручном режиме, и для проверки состояния подопытной таблицы я использовал запрос с order by.
Скрытый текст
/*сначала было 10 инсертов и запрос*/
insert into habr_test_table_220414…;
…
…
insert into habr_test_table_220414…;
commit;
select * from habr_test_table_220414 t order by t.client_id;
/*потом несколько раз повторялся кусок:*/
insert into habr_test_table_220414 select * from habr_test_table_220414;
commit;
select * from habr_test_table_220414 t order by t.client_id;
/*вот так я и строил первые тестовые данные*/
После этого я модифицировал этот запрос до финального состояния «запрос с max ()», так и не убрав order by.
Вот что получилось:
select * from
(
select c.*
, max (c.oper_id) over (partition by c.client_id) as m_o/*max_operation*/
from
(
select t.*
, max (t.amount) over (partition by t.client_id) as m_a/*max_amount*/
from habr_test_table_220414 t
order by t.client_id
) c
where c.m_a = c.amount
) where m_o = oper_id
Позже я написал «запрос с dense_rank ()» и начал сравнивать планы, но заметив этот злополучный order by в запросе с max (), удалил order by, но cost его я уже увидел и запомнил. И когда увидел cost в запросе с max () без order by сильно удивился, ведь:
Предварительный план
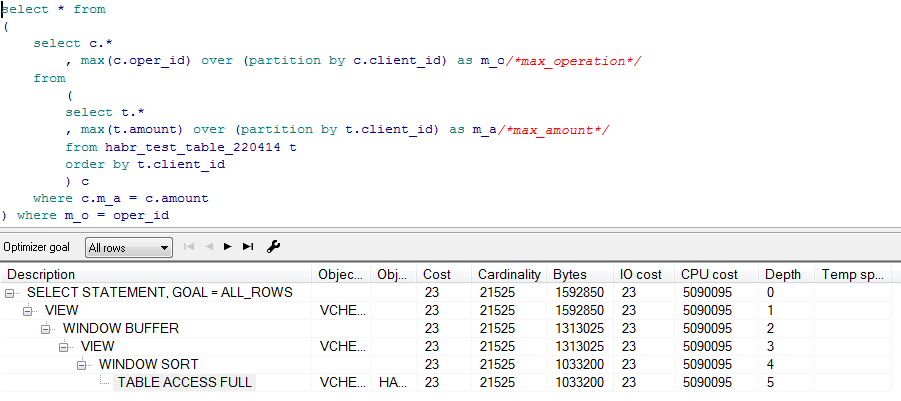 Реальный план от SQLTUNE
Реальный план от SQLTUNE
 Да и вообще, сказать что я сильно удивился — ничего не сказать… Как так получилось? Почему order by ускорил запрос в 10 раз? Решил найти ответ в трассировке. Не буду писать как именно снимать трассу в оракле, ибо это тема для отдельной статьи, да и статьи с описанием сего процесса легко найти во всемирной паутине. Предоставлю только набор скриптов, которыми я проводил трассировку и ссылку на такую статью, нашел я ее довольно давно, с тех пор она меня выручает: Скрытый текст
Ссылка на статью по включению трассировки
alter system set timed_statistics=true;
alter session set tracefile_identifier='test_for_habr_220414';
alter session set events '10046 trace name context forever, level 12';
select * from
(
select c.*
, max (c.oper_id) over (partition by c.client_id) as m_o/*max_operation*/
from
(
select t.*
, max (t.amount) over (partition by t.client_id) as m_a/*max_amount*/
from habr_test_table_220414 t
order by client_id
) c
where c.m_a = c.amount
) where m_o = oper_id;
alter session set events '10046 trace name context off';
select value from v$parameter p where name='user_dump_dest';
/*Далее расшифровываем файл трассы при помощи tkprof*/
/*в имени файла будет присутствовать 'test_for_habr_220414'*/
В трассе нас интересует кусок, который описывает действия оракла при выполнении запроса, а именно:
Скрытый текст
select * from
(
select c.*
, max (c.oper_id) over (partition by c.client_id) as m_o/*max_operation*/
from
(
select t.*
, max (t.amount) over (partition by t.client_id) as m_a/*max_amount*/
from habr_test_table_220414 t
order by client_id
) c
where c.m_a = c.amount
) where m_o = oper_id
Да и вообще, сказать что я сильно удивился — ничего не сказать… Как так получилось? Почему order by ускорил запрос в 10 раз? Решил найти ответ в трассировке. Не буду писать как именно снимать трассу в оракле, ибо это тема для отдельной статьи, да и статьи с описанием сего процесса легко найти во всемирной паутине. Предоставлю только набор скриптов, которыми я проводил трассировку и ссылку на такую статью, нашел я ее довольно давно, с тех пор она меня выручает: Скрытый текст
Ссылка на статью по включению трассировки
alter system set timed_statistics=true;
alter session set tracefile_identifier='test_for_habr_220414';
alter session set events '10046 trace name context forever, level 12';
select * from
(
select c.*
, max (c.oper_id) over (partition by c.client_id) as m_o/*max_operation*/
from
(
select t.*
, max (t.amount) over (partition by t.client_id) as m_a/*max_amount*/
from habr_test_table_220414 t
order by client_id
) c
where c.m_a = c.amount
) where m_o = oper_id;
alter session set events '10046 trace name context off';
select value from v$parameter p where name='user_dump_dest';
/*Далее расшифровываем файл трассы при помощи tkprof*/
/*в имени файла будет присутствовать 'test_for_habr_220414'*/
В трассе нас интересует кусок, который описывает действия оракла при выполнении запроса, а именно:
Скрытый текст
select * from
(
select c.*
, max (c.oper_id) over (partition by c.client_id) as m_o/*max_operation*/
from
(
select t.*
, max (t.amount) over (partition by t.client_id) as m_a/*max_amount*/
from habr_test_table_220414 t
order by client_id
) c
where c.m_a = c.amount
) where m_o = oper_id
call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ---------- ---------- ---------- Parse 1 0.01 0.00 0 1 0 0 Execute 1 0.00 0.00 0 0 0 0 Fetch 1 0.03 0.02 0 84 0 10 ------- ------ -------- ---------- ---------- ---------- ---------- ---------- total 3 0.04 0.03 0 85 0 10
Misses in library cache during parse: 1 Optimizer mode: ALL_ROWS Parsing user id: SYS
Rows Row Source Operation ----- --------------------------------------------------- 10 VIEW (cr=84 pr=0 pw=0 time=28155 us cost=23 size=1592850 card=21525) 20 WINDOW BUFFER (cr=84 pr=0 pw=0 time=28145 us cost=23 size=1313025 card=21525) 20 VIEW (cr=84 pr=0 pw=0 time=21628 us cost=23 size=1313025 card=21525) 22010 WINDOW SORT (cr=84 pr=0 pw=0 time=24393 us cost=23 size=1033200 card=21525) 22010 TABLE ACCESS FULL HABR_TEST_TABLE_220414(cr=84 pr=0 pw=0 time=5172 us cost=23 size=1033200 card=21525) Итоги Отсюда видим, что и предварительный, и реальный планы не ошибочны, никакого подвоха вроде бы как нет и можно радоваться десятикратному ускорению. А так ли это? P.S. Я так и не смог ответить на этот вопрос и все еще не верю в то, что запрос реально ускорить в разы при помощи order by. Буду и дальше пытаться выяснить этот момент, к чему и вас призываю. И да откроются перед нами сокрытые тайны оракла! P.P. S. Благодарю всех за внимание! Если вы вместе со мной проводили тест — не забываем чистить за собой базу, особенно если это прод какого нибудь банка.
Скрытый текст drop trigger habr_test_trigger_220414; drop sequence habr_test_sequence_220414; drop table habr_test_table_220414;
