Двигатель истории. Обзор видеокарты GeForce RTX 2080 Ti: часть 1
Анонс новых ускорителей семейства GeForce RTX на базе архитектуры Turing стал, не побоимся этого слова, выдающейся вехой на пути самой компании и индустрии потребительской 3D-графики в целом. Каждое по-настоящему крупное обновление дискретных GPU последних лет было кульминацией тех или иных течений, направлявших инженерную мысль за долгое время до ее воплощения в кремнии. Но Turing, для чтобы читатели в полной мере оценили значимость текущего момента, требует максимально широкого контекста, охватывающего всю историю игрового 3D на персональных компьютерах.
Сайт 3DNews.ru в прошлом году отметил свой 20-летний юбилей, а мы вспоминали, как бурно в то время эволюционировала техника. С компанией NVIDIA, основанной за четыре года до нашего издания, связано множество поворотных точек на кривой развития компьютерной графики. Скажем, немногие знают, что именно NVIDIA, а не 3dfx, в 1995 году выпустила на рынок первый массовый 3D-ускоритель на чипе NV1. Дальнейшие события известны намного лучше. Уже через четыре года GeForce 256 принес на персоналки аппаратную обработку трансформации и освещения полигонов (Transformation and Lighting, T&L), а затем, силами GeForce 3, появились программируемые шейдеры. Позднейшим из достижений NVIDIA сопоставимой важности стал высокоуровневый интерфейс CUDA для выполнения расчетов общего назначения, которые со временем стали едва ли не более важной задачей для GPU, чем рендеринг графики.
Впоследствии графические процессоры отправились в спокойное плавание, не отмеченное радикальными переменами в функциях железа и принципах программирования. Но вот спустя 11 лет после анонса CUDA основатель NVIDIA Дженсен Хуанг вынес на сцену видеокарту под девизом Graphics Reinvented, и, вы знаете, в данном случае высокопарные слова совершенно уместны. Ведь Turing впервые среди потребительских GPU обеспечивает специализированное ускорение расчетов искусственного интеллекта и трассировки лучей в реальном времени. Можно не сомневаться: если игровая индустрия поддержит эти инициативы, а хватка NVIDIA на рынке сейчас как никогда сильна, то мы стали очевидцами очередной смены эпох.

Представляем первую часть обзора видеокарт семейства GeForce RTX, в которой нас ждет подробный анализ архитектуры Turing и презентация устройств на ее основе. Масштаб изменений по сравнению с предыдущим поколением, Pascal, вполне заслуживает отдельной статьи, а эмпирическое тестирование GeForce RTX 2080 Ti в любом случае придется отложить до 19 сентября, когда истекает запрет на публикацию бенчмарков и в нашем распоряжении появятся первые образцы устройств.
⇡#Графические процессоры семейства Turing
Перед глубоким погружением в архитектуру GeForce RTX составим общее представление о самом железе, которое выпустила NVIDIA. Благо, кремний Turing по-прежнему характеризуют метрики, применимые к GPU предыдущих поколений, а назначение и принцип работы новых функциональных блоков мы изучим позже.
В отличие от Pascal и более ранних поколений GPU, Turing с первого дня существует в виде трех процессоров — TU102, TU104 и TU106. Как видим, компании пришлось сменить привычную номенклатуру, в которой первой буквой всегда была G, а вторая означает название микроархитектуры, ведь сочетание GT уже занято старой архитектурой Tesla. Чипы выпускаются по эксклюзивному контракту с фабрикой TSMC, где им выделен собственный технологический узел 12 нм FFN (это буквально означает FinFET NVIDIA).
| Производитель | NVIDIA | ||||||
| Название | GP104 | GP102 | GP100 | GV100 | TU106 | TU104 | TU102 |
| Микроархитектура | Pascal | Pascal | Pascal | Volta | Turing | Turing | Turing |
| Техпроцесс, нм | 16 nm FinFET | 16 nm FinFET | 16 nm FinFET | 12 нм FFN | 12 нм FFN | 12 нм FFN | 12 нм FFN |
| Число транзисторов, млн | 7 200 | 12 000 | 15 300 | 21 100 | 10 800 | 13 600 | 18 600 |
| Площадь чипа, мм2 | 314 | 471 | 610 | 815 | 445 | 545 | 754 |
| Конфигурация SM/TPC/GPC | |||||||
| Число SM | 20 | 30 | 60 | 84 | 36 | 48 | 72 |
| Число TPC | 20 | 30 | 30 | 42 | 18 | 24 | 36 |
| Число GPC | 4 | 6 | 6 | 7 | 3 | 6 | 6 |
| Конфигурация потокового мультипроцессора (SM) | |||||||
| FP32-ядра | 128 | 128 | 64 | 64 | 64 | 64 | 64 |
| FP64-ядра | 4 | 4 | 32 | 32 | 2 | 2 | 2 |
| INT32-ядра | Н/Д | Н/Д | Н/Д | 64 | 64 | 64 | 64 |
| Тензорные ядра | Н/Д | Н/Д | Н/Д | 8 | 8 | 8 | 8 |
| RT-ядра | Н/Д | Н/Д | Н/Д | Н/Д | 1 | 1 | 1 |
| Программируемые вычислительные блоки GPU | |||||||
| FP32-ядра | 2 560 | 3 840 | 3 840 | 5 376 | 2 304 | 3 072 | 4 608 |
| FP64-ядра | 80 | 120 | 1 920 | 2 688 | 72 | 96 | 144 |
| INT32-ядра | Н/Д | Н/Д | Н/Д | 5 376 | 2 304 | 3 072 | 4 608 |
| Тензорные ядра | Н/Д | Н/Д | Н/Д | 672 | 288 | 384 | 576 |
| RT-ядра | Н/Д | Н/Д | Н/Д | Н/Д | 36 | 48 | 72 |
| Блоки фиксированной функциональности | |||||||
| TMU (блоки наложения текстур) | 160 | 240 | 240 | 336 | 144 | 192 | 288 |
| ROP | 64 | 96 | 128 | 128 | 64 | 64 | 96 |
| Конфигурация памяти | |||||||
| Объем кеша L1 / текстурного кеша, Кбайт | 48 | 48 | 24 | ≤ 128 из 128, общий с разделяемой памятью | 32/64 из 96 (общий с разделяемой памятью) | 32/64 из 96 (общий с разделяемой памятью) | 32/64 из 96 (общий с разделяемой памятью) |
| Объем разделяемой памяти / SM, Кбайт | 96 | 96 | 64 | ≤ 96 из 128 (общий с кешем L1) | 32/64 из 96 (общий с кешем L1) | 32/64 из 96 (общий с кешем L1) | 32/64 из 96 (общий с кешем L1) |
| Объем регистрового файла / SM, Кбайт | 256 | 256 | 256 | 256 | 256 | 256 | 256 |
| Объем регистрового файла / GPU, Кбайт | 5 120 | 7 680 | 15 360 | 21 504 | 9 216 | 12 288 | 18 432 |
| Объем кеша L2, Кбайт | 2 048 | 3 072 | 4 096 | 6 144 | 4 096 | 4 096 | 6 144 |
| Разрядность шины RAM, бит | 256 | 384 | 4 096 | 4 096 | 256 | 256 | 384 |
| Тип микросхем RAM | GDDR5/GDDR5X | GDDR5X | HBM2 | HBM2 | GDDR6 | GDDR6 | GDDR6 |
| Шина NVLINK | Н/Д | Н/Д | 4 × NVLink 1.0×8 | 6 × NVLink 2.0×8 | Н/Д | 1 × NVLink 2.0×8 | 2 × NVLink 2.0×8 |
В действительности, «нанометраж» фотолитографического процесса редко соответствует своему прямому смыслу — длине транзисторного затвора, а та, в свою очередь, ничего не говорит о зазорах между элементами и реальной плотности их размещения. В данной ситуации TSMC не скрывает того факта, что ее технология 12 нм является вариантом узла 16 нм FinFET+ с повышенной плотностью и сниженными утечками тока. Потому не удивительно, что по отношению декларируемого числа транзисторов к площади кристалла все три чипа Turing практически не отличаются от старшего Pascal (GP100), который был получен на «чистом» техпроцессе 16 нм. Впрочем, по сравнению GP104 (GeForce GTX 1070/1080) у Turing все же есть прирост плотности около 6%.
Согласно количеству элементов можно распределить три «Тьюринга» по весовым категориям, заданным процессорами поколения Pascal. TU104 ближе всего к GP102 (GeForce GTX 1080 Ti), а младший чип, TU106, за неимением ближайшего аналога, соответствует GP104. Заметьте, насколько при смене поколений выросли площади кремния и транзисторные бюджеты (на 42% и 50% соответственно в паре GP104-TU106 и на 16% и 13% у GP102-TU104).

Блок-схема графического процессора NVIDIA TU106
В авангарде модельного ряда Turing находится TU102. Появление чипа с таким номером в первые дни новой архитектуры уже необычно, если вспомнить, сколько времени понадобилось NVIDIA, чтобы отправить в игровой сектор старших представителей предыдущих поколений. Но помимо этого, сам GPU беспрецедентно велик по действующим стандартам массового рынка. При площади 754 мм2 и транзисторном бюджете 18,6 млрд он уступает лишь своему серверному предшественнику GV100 (815 мм2 и 21,1 млрд транзисторов) на архитектуре Volta, а GP102 (471 мм2 и 12 млрд транзисторов) превосходит на 60% и 55% соответственно. К слову, позиция TU100, которую по аналогии с Pascal и Volta мог бы занять еще более амбициозный чип для датацентров на базе Turing (со всеми полагающимися атрибутами в виде памяти HBM2 и NVLink в качестве основной шины), пока вакантна.При сравнении с Pascal по количеству 32-битных ядер CUDA и блоков фиксированной функциональности (TMU и ROP) становится очевидно, что в лице Turing мы имеем дело с кардинально отличной микроархитектурой: TU106 и TU104 заметно уступают своим предкам GP104 и GP102. Только старший Turing не идет на компромисс по количеству ядер CUDA и блоков наложения текстур просто за счет колоссальных размеров чипа.

Блок-схема графического процессора NVIDIA TU104
Как получилось, что столь крупные GPU оказались сравнительно небогаты CUDA-ядрами, объясняется массой факторов, среди которых ведущую роль играет появление вычислительных блоков трех новых типов: тензорные ядра, ядра трассировки лучей (RT в таблице), а также ядра целочисленных вычислений (INT32). Кроме того, у новых GPU в полтора-два раза разбух кеш второго уровня и увеличилась площадь управляющей логики за счет реорганизации CUDA-ядер в пределах потокового мультипроцессора (SM). Все эти изменения мы также обсудим в следующих разделах обзора.
Поскольку смена техпроцесса на условные 12 нм вряд ли радикально подействовала на рабочие частоты GPU, может сложиться впечатление, что создатели Turing пожертвовали стандартной шейдерной производительностью в пользу новых специализированных функций. Но не стоит делать выводы по табличным данным. При подробном рассмотрении мы убедимся, даже если не брать в расчет долю транзисторов, которую «съели» тензорные и RT-ядра, что Turing в целом стал более сложной и «широкой» архитектурой по сравнению с Pascal, и это, по крайней мере в теории, послужило повышенной эффективности в шейдерных вычислениях.
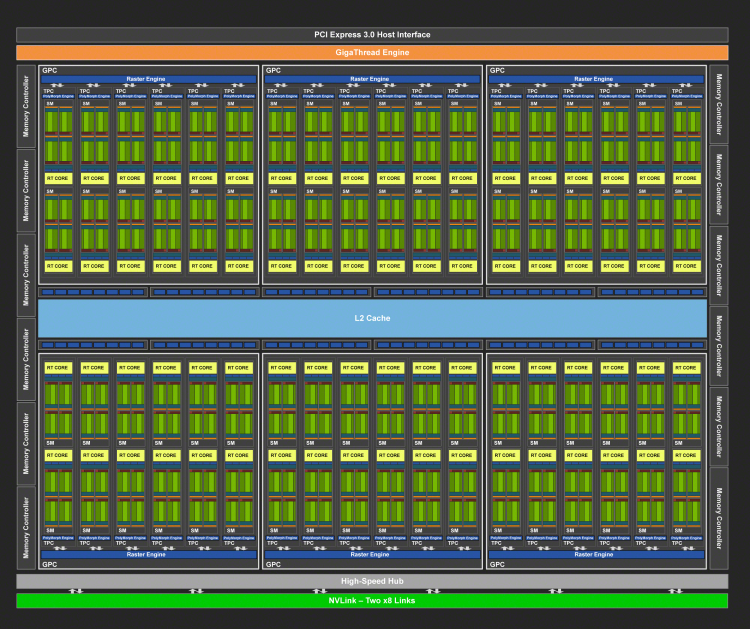
Блок-схема графического процессора NVIDIA TU102
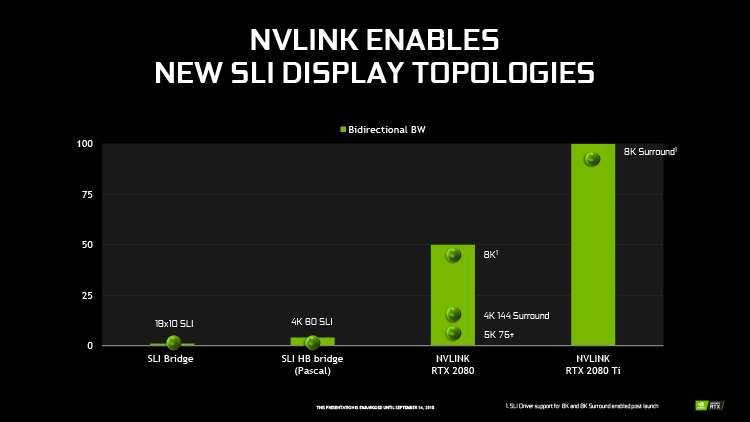
Завершая краткий обзор кремния Turing, отметим поддержку чрезвычайно быстрого интерфейса NVLink, который используется в кластерах HPC-ускорителей Tesla на основе чипов GP100 и GV100, и, соответственно, новых аппаратных мостиков. Чип TU104 имеет несет один порт NVLink второго поколения с пропускной способностью 50 Гбайт/с (по 25 Гбайт/с в каждую сторону), а TU102 — два порта. Новая шина здесь выступает в качестве замены выделенной шины SLI (возможные конфигурации по-прежнему ограничены двумя GPU), и скорости одного такого порта вполне достаточно для передачи кадрового буфера с разрешением 8К в режиме AFR (Alternate Frame Rendering).
Но обратите внимание, что при использовании двух портов пропускная способность NVLink уже находится в зоне возможностей оперативной памяти бюджетных игровых видеокарт. При неграфических вычислениях с помощью нескольких чипов в связке NVLink память соседней видеокарты уже выступает как дальний сегмент локальной RAM и в перспективе такой подход можно привлечь для реализации сложных алгоритмов мультиадаптерного рендеринга под Direct3D 12 (конвейеризация кадров). В отличие от старого интерфейса SLI, который используется только для передачи кадровых буферов, коммуникация нескольких GPU по такой шине, как NVLink, разрешена в рамках эксплицитного режима Multi-Adapter под Direct3D 12.
⇡#Модельный ряд GeForce RTX 20
Семейство GeForce RTX на данном этапе представлено тремя устройствами — RTX 2070, RTX 2080 и RTX 2080 Ti — основанными на чипах TU106, TU104 и TU102 соответственно. Но среди них только RTX 2070 достался полностью функциональный графический процессор, в то время как TU104 и TU102 оказались тем или иным образом «порезаны» в своих потребительских воплощениях. RTX 2080 и RTX 2080 Ti лишились соответственно 2 и 4 из 48 и 72 SM, которые есть в оригинальных GPU.
Опираясь на заявленные частоты и конфигурацию CUDA-ядер мы можем сравнить теоретическое быстродействие GeForce RTX и ускорителей поколения Pascal в 32-битных операциях с плавающей запятой. В этом отношении RTX 2070 находится в промежутке между GTX 1070 и GTX 1080. Следующая по старшинству новинка, RTX 2080, заняла место между GTX 1080 и GTX 1080 Ti, а RTX 2080 Ti, как и положено флагману, оставил GTX 1080 Ti позади.
Сказывается преимущество по количеству активных CUDA-ядер, ведь верхние значения тактовых частот Turing находятся в примерном соответствии с показателями GeForce GTX 1070/1080 и GTX 1080 Ti. Это хорошие новости, если вспомнить, насколько крупнее GPU в новых видеокартах, однако NVIDIA пришлось немного понизить базовые частоты трех чипов, чтобы оставить в термопакете запас на комбинированную нагрузку с участием тензорных и RT-ядер, а TDP ускорителей (помимо старшей модели) предсказуемо увеличился.
| Производитель | NVIDIA | |||||
| Модель | GeForce GTX 1070 | GeForce GTX 1080 | GeForce GTX 1080 Ti | GeForce RTX 2070 | GeForce RTX 2080 | GeForce RTX 2080 Ti |
| Графический процессор | ||||||
| Название | GP104 | GP104 | GP102 | TU102 | TU104 | TU106 |
| Микроархитектура | Pascal | Pascal | Pascal | Turing | Turing | Turing |
| Техпроцесс, нм | 16 нм FinFET | 16 нм FinFET | 16 нм FinFET | 12 нм FFN | 12 нм FFN | 12 нм FFN |
| Число транзисторов, млн | 7 200 | 7 200 | 12 000 | 10 800 | 13 600 | 18 600 |
| Тактовая частота, МГц: Base Clock / Boost Clock | 1 506 / 1 683 | 1 607 / 1 733 | 1 480 / 1 582 | 1 410 / 1 620 (Founders Edition: 1 410 / 1 710) | 1 515 / 1 710 (Founders Edition: 1 515 / 1 800) | 1 350 / 1 545 (Founders Edition: 1 350 / 1 545) |
| Число шейдерных ALU | 1 920 | 2 560 | 3 584 | 2304 | 2944 | 4352 |
| Число блоков наложения текстур | 120 | 160 | 224 | 144 | 184 | 272 |
| Число ROP | 64 | 64 | 88 | 64 | 64 | 88 |
| Оперативная память | ||||||
| Разрядность шины, бит | 256 | 256 | 352 | 256 | 256 | 352 |
| Тип микросхем | GDDR5 SDRAM | GDDR5X SDRAM | GDDR5X SDRAM | GDDR6 SDRAM | GDDR6 SDRAM | GDDR6 SDRAM |
| Тактовая частота, МГц (пропускная способность на контакт, Мбит/с) | 2 000 (8 000) | 1 250 (10 000) | 1 376,25 (11 010) | 1 750 (14 000) | 1 750 (14 000) | 1 750 (14 000) |
| Объем, Мбайт | 8 192 | 8 192 | 11 264 | 8 192 | 8 192 | 11 264 |
| Шина ввода/вывода | PCI Express 3.0×16 | PCI Express 3.0×16 | PCI Express 3.0×16 | PCI Express 3.0×16 | PCI Express 3.0×16 | PCI Express 3.0×16 |
| Производительность | ||||||
| Пиковая производительность FP32, GFLOPS (из расчета максимальной указанной частоты) | 6 463 | 8 873 | 11 340 | 7 465 / 7 880 (Founders Edition) | 10 069 / 10 598 (Founders Edition) | 13 448 / 13 448 (Founders Edition) |
| Производительность FP32/FP64 | 1/32 | 1/32 | 1/32 | 1/32 | 1/32 | 1/32 |
| Пропускная способность оперативной памяти, Гбайт/с | 256 | 320 | 484 | 448 | 448 | 616 |
| Вывод изображения | ||||||
| Интерфейсы вывода изображения | DL DVI-D, DisplayPort 1.3/1.4, HDMI 2.0b | DL DVI-D, DisplayPort 1.3/1.4, HDMI 2.0b | DisplayPort 1.3/1.4, HDMI 2.0b | DisplayPort 1.4a, HDMI 2.0b | DisplayPort 1.4a, HDMI 2.0b | DisplayPort 1.4a, HDMI 2.0b |
| TDP, Вт | 150 | 180 | 250 | 175/185 (Founders Edition) | 215/225 (Founders Edition) | 250/260 (Founders Edition) |
| Розничная цена (США, без налога), $ | 349 (рекомендованная) / 399 (Founders Edition, nvidia.com) | 499 (рекомендованная) / 549 (Founders Edition, nvidia.com) | НД (рекомендованная) / 699 (Founders Edition, nvidia.com) | 499 (рекомендованная) / 599 (Founders Edition, nvidia.com) | 699 (рекомендованная) / 799 (Founders Edition, nvidia.com) | 999 (рекомендованная) / 1 199 (Founders Edition, nvidia.com) |
| Розничная цена (Россия), руб. | НД (рекомендованная) / 31 590 (Founders Edition, nvidia.ru) | НД (рекомендованная) / 45 790 (Founders Edition, nvidia.ru) | НД (рекомендованная) / 52 990 (Founders Edition, nvidia.ru) | НД (рекомендованная) / 47 990 (Founders Edition, nvidia.ru) | НД (рекомендованная) / 63 990 (Founders Edition, nvidia.ru) | НД (рекомендованная) / 95 990 (Founders Edition, nvidia.ru) |
⇡#Оперативная память GDDR6
Во всем семействе GeForce RTX применяются чипы памяти GDDR6 с пропускной способностью 14 Гбит/с на контакт. При этом два младших чипа имеют 256-битую, а TU102 — 384-битную шину памяти. В потребительские Turing NVIDIA устанавливает по одной микросхеме объемом 1 Гбайт на каждый 32-битный контроллер. Как следствие, объем RAM достигает 8 Гбайт в RTX 2070/2080 и 11 Гбайт в RTX 2080 Ti. В RTX 2080 Ti отключили один из двенадцати контроллеров памяти, которые есть в кремнии GP102, из-за чего вся шина памяти сузилась с 384 до 352 бит и был потерян 1 Гбайт RAM.
Что касается самой GDDR6, то новый тип микросхем имеет немного принципиальных отличий от GDDR5X и, в сухом остатке, предлагает более высокие тактовые частоты при таком же стандартном напряжении питания (1,35 В).
Ключевая особенность стандарта GDDR6 в том, что он подразумевает наличие в каждом чипе двух полностью независимых 16-битных канала с собственными шинами команд и данных (в отличие от единого 32-битного интерфейса GDDR5 и псевдо-независимых каналов в GDDR5X). Это открывает массу возможностей для эффективного использования пропускной способности. Ведь чем больше каналов, тем меньше данных, при должном управлении со стороны GPU, «застревает» в ожидании обновления страниц и прочих длительных операций. Кроме того, узкая 16-битная шина в два раза по сравнению с 32-битной шиной GDDR5X сокращает размер кванта данных (32 и 64 байт соответственно при характеристике Prefetch 16n), который процессор при обращении к RAM помещает в кеш второго уровня, а значит, системы кешей с длиной слова в 32 байт не заполняются «мусорными» данными и работают более эффективно.
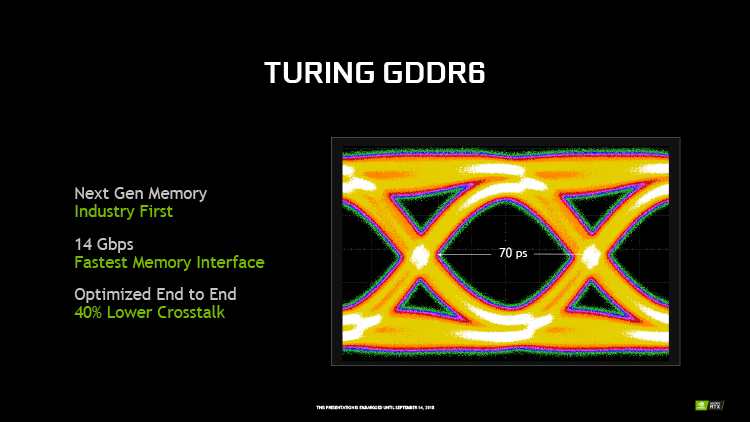
Другой отличительной чертой стандарта GDDR6 является возможность работать в режимах DDR либо QDR (с передачей двух и четырех бит данных на цикл сигнала соответственно) при неизменной пропускной способности памяти (ПСП), только в режиме DDR контроллеру придется поддерживать вдвое более высокую частоту шины данных. По правде говоря, с максимальной на сегодня ПСП для GDDR6 в 16 Гбит/с на контакт частота шины данных на уровне 8 ГГц не кажется реальной возможностью для современных GPU.
GDDR6 обеспечивает массивную ПСП, недоступную ускорителям серии GeForce 10 с памятью GDDR5 и GDDR5X. Даже с «урезанной» шиной GeForce RTX 2080 Ti достигает 616 Гбайт/с. А это, на минуточку, больше, чем у Radeon RX Vega 64 (484 Гбайт/с), которая использует более дорогую и сложную память HBM2. Кроме того, NVIDIA продолжила развитие алгоритмов компрессии данных в шине памяти, благодаря которым эффективная ПСП GeForce RTX 2080 Ti оценивается в 50% больше по сравнению с GeForce GTX 1080 Ti.
⇡#Видеокарты Founders Edition, цены
Обратите внимание, что для видеокарт под маркой Founders Edition в таблице указаны не только отдельные цены, но и собственные тактовые частоты и показатели TDP. Еще в прошлом поколении карты Founders Edition, которыми NVIDIA насытила первую волну поставок и затем продолжила продавать через собственный интернет-магазин, формально не считались референсными моделями. Но в данном случае с первого дня на рынок поступит множество видеокарт оригинального дизайна, и Founders Edition станет лишь одним из равноправных предложений с заводским разгоном и качественной системой охлаждения. Собственно референсные характеристики станут ориентиром для упрощенных модификаций GeForce RTX от сторонних производителей, не претендующих на серьезный оверклокинг.
Старт розничных продаж GeForce RTX 2080 и RTX 2080 Ti назначен на 20 сентября, а прибытие RTX 2070 ожидается в следующем месяце. Но едва ли не главная новость всего события — это скандальные цены новинок. Если сравнивать новые видеокарты со старыми в соответствии с их положением в модельном ряду, то 70-я модель стала дороже на $150 (с $349 до $499), а 80-я — на $200 (с $499 до $699). Наценка на Founders Edition тоже возросла, до $100 за соответствующие версии RTX 2070 и RTX 2080.

Конечно, GeForce RTX обладает заведомо более высокой производительностью, не говоря о новых функциях рендеринга, но ведь в прошлые годы мы привыкли пожинать плоды прогресса «бесплатно» относительно цен уходящего поколения. Сейчас же получается, что GeForce RTX 2070 является денежным эквивалентом GTX 1080, а RTX 2080, в свою очередь, GTX 1080 Ti. При всем этом по теоретическому быстродействию без учета оптимизаций, а также тензорных и RT-вычислений, в пересчете на доллар Turing не сделал ни шага вперед по сравнению с Pascal и даже уступает последнему. Но, помня о значительной разнице между архитектурами, все-таки оставим последнее слово в этом вопросе за бенчмарками.
Что касается GeForce RTX 2080 Ti, то по цене это, ни дать ни взять, уровень серии TITAN, ведь рекомендованная стоимость флагмана составляет $999, а Founders Edition — $1199. В России это будет первый GeForce, который подошел к отметке в 100 тыс. рублей. На этой звонкой ноте мы прервем разговор о самих видеокартах до публикации второй части статьи с результатами тестирования и приступим к анализу архитектурных особенностей чипов Turing.
⇡#Архитектура Turing: потоковый мультипроцессор
Большая часть нововведений Turing сосредоточена внутри потокового мультипроцессора (Streaming Multiprocessor, SM). Но для начала рассмотрим архитектуру GPU, так сказать, с высоты птичьего полета. Как и в Pascal, потоковые мультипроцессоры находятся внутри блоков TPC (Texture Processing Cluster) вместе с PolyMorph Engine, выполняющим функции T&L и тесселяции. Turing обладает таким же соотношением между числом ядер CUDA и геометрических движков, как Pascal, но сами PolyMorph Engine претерпели определенные изменения, о которых мы расскажем позже. В свою очередь, несколько TPC входят в состав наиболее крупной организационной единицы — GPC (Graphics Processing Cluster), другой частью которой является блок Raster Engine, который выполняет самые ранние стадии рендеринга: отсечение невидимых пикселов и растеризацию полигонов.
По структуре SM новая архитектура во многом повторяет Volta и далеко ушла от Pascal. Пока мы изучим изменения, которые относятся к исполнению операций над числами с плавающей запятой одинарной точности (FP32) и не затрагивают вычислительных блоков нового типа (тензорных и RT).
В потребительских GPU семейства Pascal потоковый мультипроцессор разделен на четыре секции, каждая из которых содержит 32 ядра CUDA, снабженных собственным планировщиком и двумя портами диспетчера команд. За один такт процессора планировщик отправляет на исполнение ряд однотипных инструкций из группы 32 независимых цепочек (последняя называется warp в терминологии NVIDIA), а блок CUDA-ядер исполняет их также за один такт. Но благодаря второму порту диспетчера допустимо одновременное исполнение следующей порции инструкций из того же warp«а на простаивающих в данный момент ядрах. Таким образом, Pascal является суперскалярной архитектурой, которая наряду с потоковым параллелизмом (Thread Level Parallelism, TSP), неотъемлемым для GPU как массивно-параллельных процессоров, извлекает из нагрузки параллелизм команд (Instruction Level Parallelism, ILP).
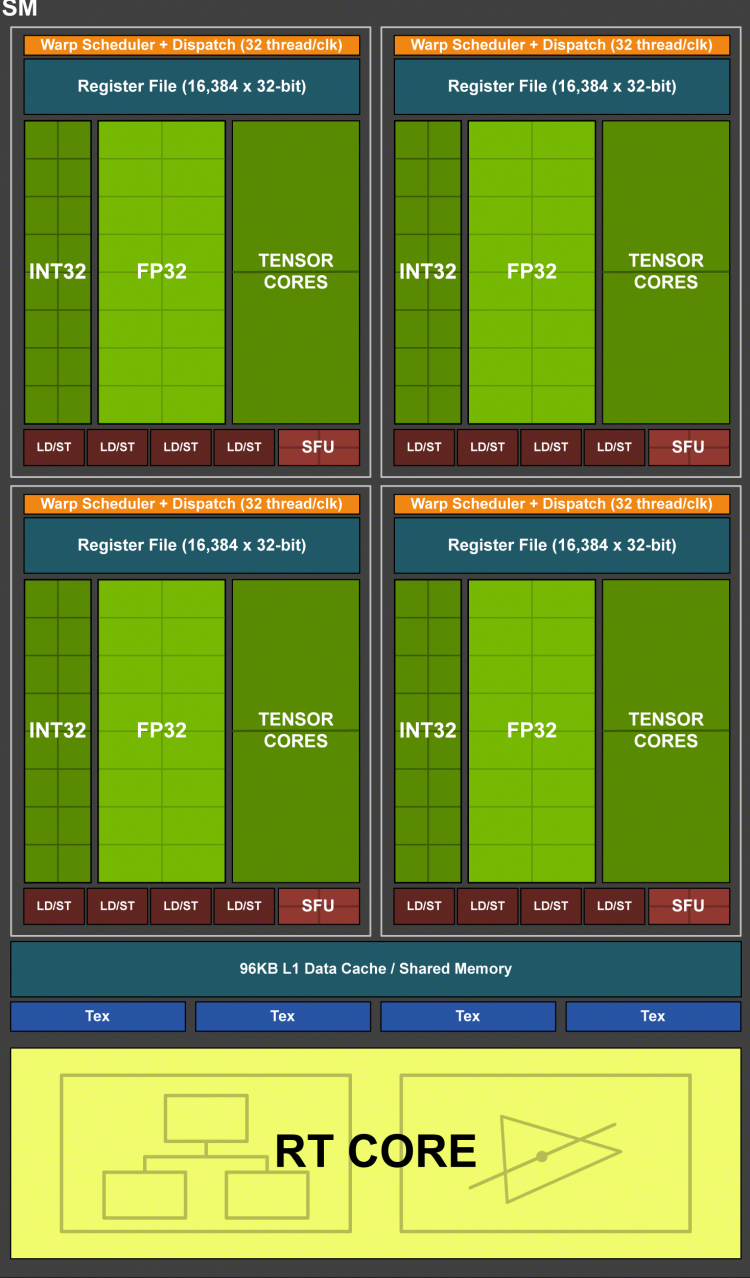
Блок-схема потокового мультипроцессора (SM) в архитектуре Turing
В Volta и Turing все так же есть четыре секции на один SM, но одна секция содержит 16 ядер FP32 — вдвое меньше, чем в Pascal. Поскольку warp в модели программирования NVIDIA по-прежнему состоит из 32 цепочек инструкций, разработчикам пришлось вернуться к принципу, характерному для давнишней архитектуры Fermi: блок из 16 CUDA-ядер исполняет 32 инструкции за два такта процессора.
За счет уменьшенного объема SM в Volta и Turing возросло число планировщиков в пересчете на общий массив CUDA-ядер. Как следствие, GPU обрабатывает одновременно больше цепочек инструкций. Однако планировщик внутри секции SM теперь имеет только один порт диспетчера. В результате потери второго порта Volta и Turing лишились возможности извлекать из задачи ILP в пользу увеличенного TLP. Вопрос, какой тип параллелизма более выгоден для той или типичной нагрузки на GPU, не имеет простого ответа, но резонно предположить, что в свете общего усложнения структуры SM расход транзисторного бюджета на логику дополнительного диспетчера инженеры NVIDIA просто сочли неоправданной инвестицией.
Другой особенностью, которую Turing получил в наследство от Volta, является независимая планировка потоков (Independent Thread Scheduling, ITS). В общем виде это означает, что процессор отслеживает состояние выполнения каждой цепочки инструкций, в то время как в Pascal такие понятия, как счетчик команд и стек вызовов, являются общими для всех цепочек warp«a. Планировщики Volta и Turing позволяют по отдельности завершать, приостанавливать и заново группировать выполнение цепочек для максимального насыщения CUDA-ядер.
Наконец, Volta и Turing объединяет возможность одновременного исполнения операций с вещественными (FP) и целочисленными (INT) данными. Целочисленные вычисления используются в задачах применения заранее сформированных сетей машинного обучения (Inference), но также занимают большую долю операций типичной шейдерной нагрузки (по оценке NVIDIA, на каждые 100 операций FP32 в современных приложениях приходится 36 целочисленных операций). В предшествующих архитектурах целочисленные ALU привязаны к CUDA-ядрам, поэтому весь блок ядер в секции SM может в рамках такта выполнять либо операции с плавающей запятой, либо целочисленные. В Volta и Turing целочисленные ALU выделены в собственный блок ядер, за счет чего допустима смешанная нагрузка с одновременной работой над данными двух разных типов. Число INT- и FP-ядер в секции равно 16, поэтому однопортовый диспетчер инструкций, отправляющий по 32 команды за такт, может в течение двух тактов полностью загрузить блоки INT-и FP-ядер, каждому из которых также требуется два такта, чтобы исполнить команды. Зримым результатом отделения целочисленных ядер в Volta и Turing является сниженная с 6 до 4 циклов латентность FMA (Fused Multiply Add) — пожалуй, наиболее важной операции для современных GPU.
В структуре набортной памяти графического процессора Turing также повторяет архитектуру Volta. Здесь главным изменением новых GPU по сравнению с Pascal стало слияние кеша L1 с разделяемой памятью (Shared Memory). Разница между этими типами памяти состоит в том, что содержимое Shared Memory эксплицитно определяет код исполняемой на GPU программы, в то время как данные, попадающие в L1, процессор выбирает на свое усмотрение. Shared Memory в предыдущих архитектурах отличается более высокой пропускной способностью и относительно низкой латентностью по сравнению с L1, но Volta и Turing распространили эти преимущества и на кеш первого уровня.
Известно, что Volta способна гибко регулировать соотношение объемов L1 и Shared Memory, вплоть до полного отсутствия последней. В документации NVIDIA не вполне очевидно, как это работает в Turing, но складывается впечатление, что допустимы только два варианта разбивки — 32 и 64 Кбайт из общих 96 Кбайт в пользу того или иного типа памяти. Кроме того, кеш L1 в Volta может хранить операции записи (store), но остается под вопросом, есть ли такая возможность в Turing.
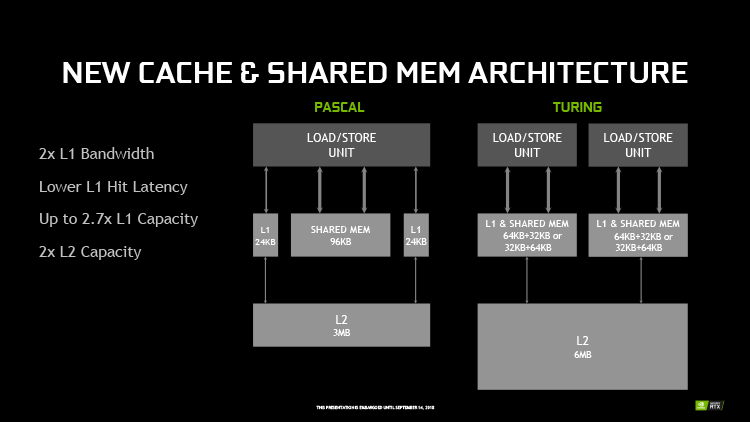
Объем регистрового файла во всех чипах Volta и Turing составляет 256 Кбайт на SM — столько же, как в Pascal, но поскольку сам SM вдвое сократили по числу ядер CUDA, общий объем регистрового файла заметно вырос. Кроме того, NVIDIA внедрила в каждой секции SM отдельный кеш инструкций L0 вместо общего для SM буфера инструкций. И, наконец, кеши второго уровня выросли до 4 Мбайт в чипах TU104/TU106 и 6 Мбайт в TU102.
Все оптимизации архитектуры, которые NVIDIA внедрила в Turing, по собственным тестам компании, повысили скорость выполнения шейдерной нагрузки на 50% по сравнению с Pascal в пересчете на ядро CUDA при равной тактовой частоте.
Следующая страница →
Полный текст статьи читайте на 3DNews
